The way we search is changing rapidly. For years, we’ve learnt to translate our thoughts into keywords, to make it easy for Google or Amazon
Do you dream of quitting your job, even if things are going quite well? Do you fantasize about doings something totally different, perhaps changing careers,
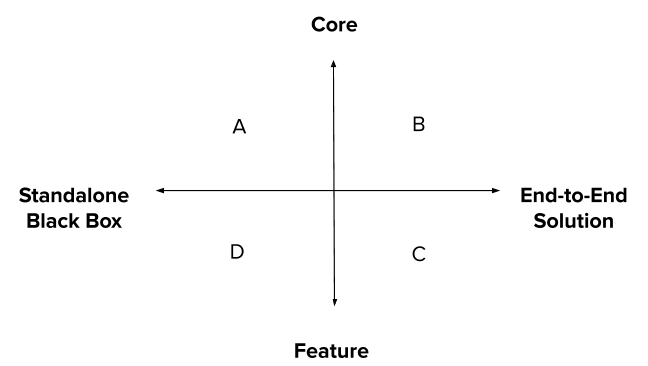
In “What it takes to Build Effective Search”, we discussed why Ecommerce search relevance is hard to get right without significant investment. In this article,
Onboarding a search tool like Elastic or Algolia is easy to do — create an account, install a library, upload a catalog and boom, you’ll
Are heading towards a post-work dopamine-addicted future? An odd affliction seems to have struck a significant percentage of my social circle. These are educated folk
On Emotions Exhilaration and disbelief, a constant thrill ride,With the perennail fear of invalidation side by side.With OpenAI releases sweeping over you like an endless
Late 2020, after I parted ways with Semantics3 – a startup I co-founded between 2011-2020 – I made an attempt to chronicle my learnings from
Switching from a tech role at a startup to one at an established tech company should be relatively easy. Engineering, product and design skills are,

A look at best selling categories and brands in the US from a basket of “high priority” goods Amazon recently announced that it would focus on

On 4x price increases, rapid price fluctuations, upstart brands and fake listings COVID-19 has led to a spike in demand for products like hand sanitizers
A playbook for building ML powered products, teams and businesses Building and selling machine learning (ML) products is hard. The underlying technology keeps evolving, requiring
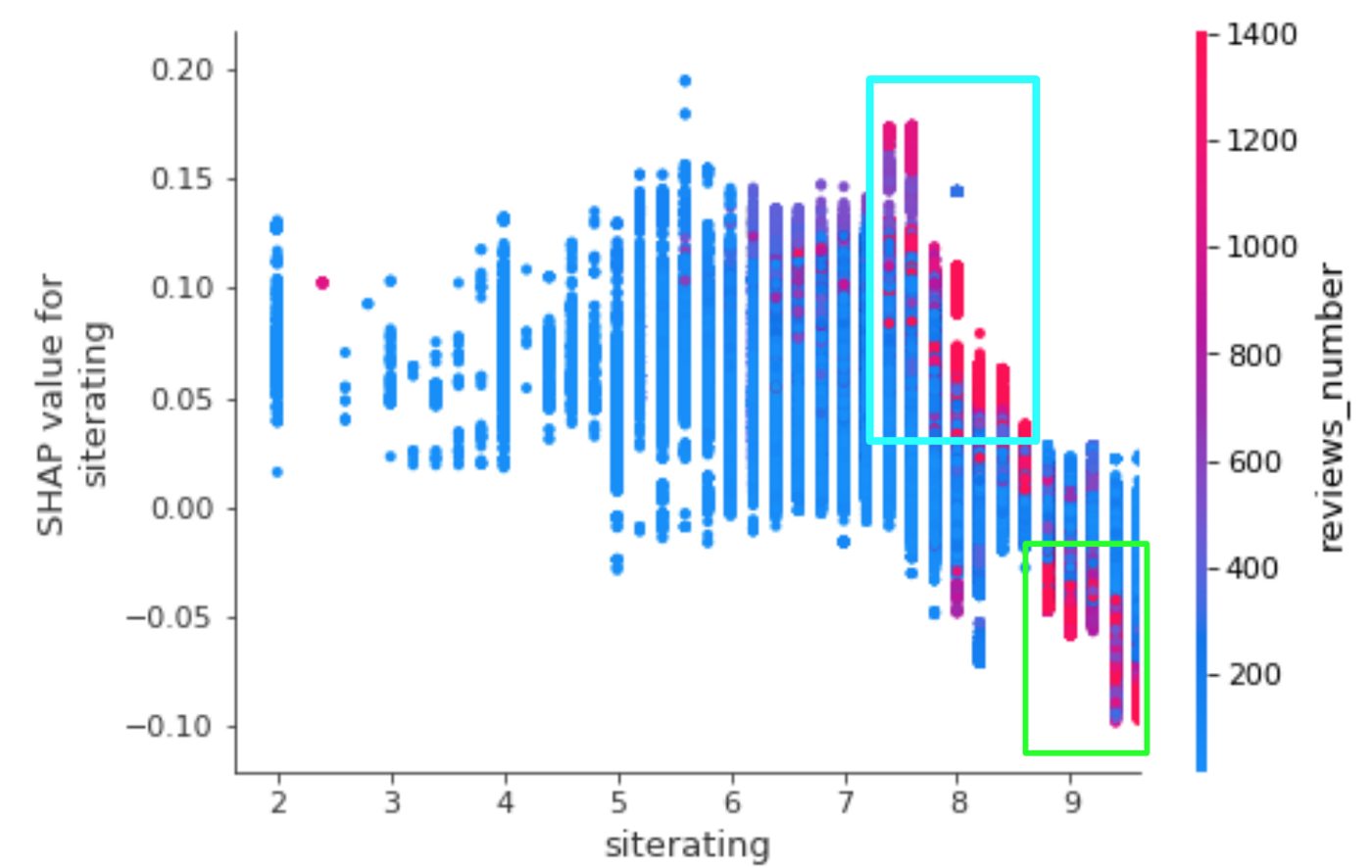
Can the demand for an item be predicted before its market launch? How about 1 month into launch, once the initial numbers are in? Which

Attribute Extraction from ecommerce data – the generation of structured fields from unstructured text – is a popular product offering of ours. Our customers use it

This is the second in a multi-part series in which we attempt to unearth dynamics of the shipping industry, by analyzing publicly available import shipment
Each December, I religiously set a list of personal targets for the new year. Usually, the first item on this list is a reading target,
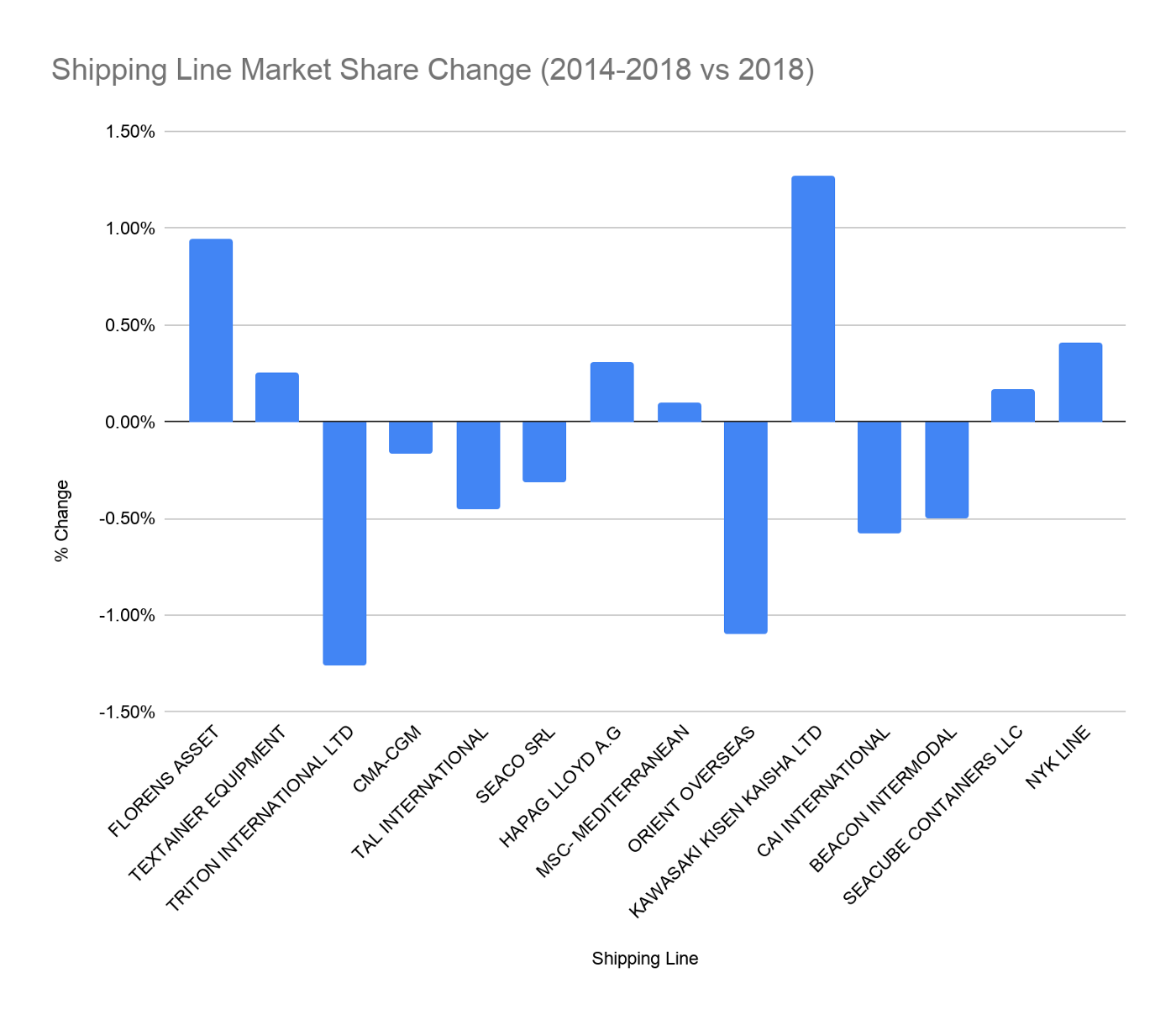
This is the first in an article series in which we attempt to unearth dynamics of the shipping industry, by analyzing publicly available import shipment
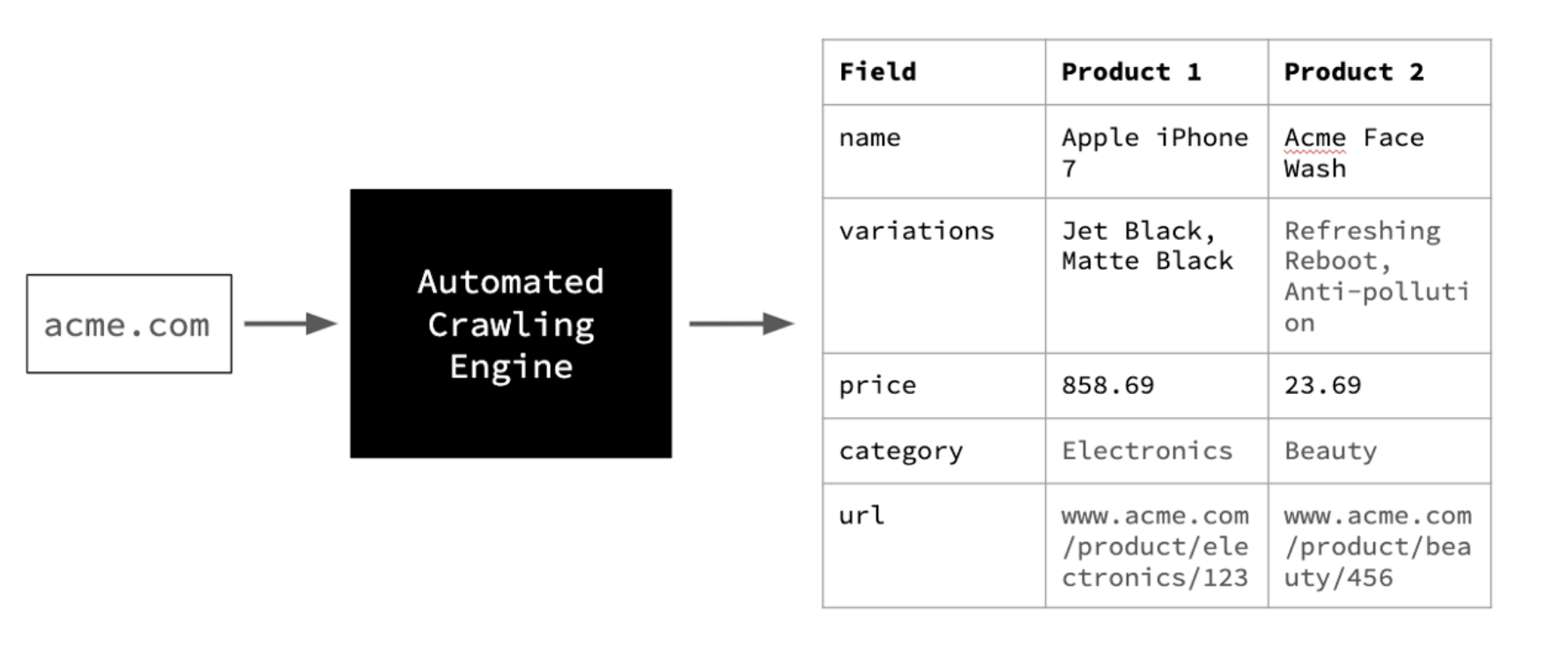
Writing crawlers to extract data from websites is a seemingly intractable problem. The issue is that while it’s easy to build a one-off crawler, writing

I wrote this post back in 2017, but left it languishing in my drafts folder. Present day reflection at the end of this article. “Garbage

If you were to take a flight from India to the United States, to which country would the carbon emissions produced be attributed to? To
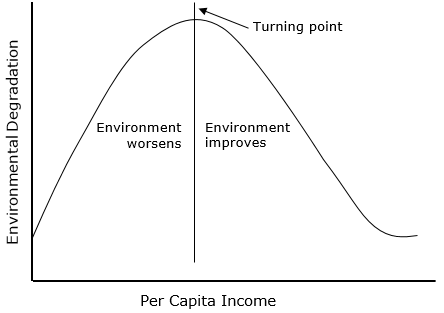
I have been struck by how important measurement is to improving the human condition. You can achieve incredible progress if you set a clear goal
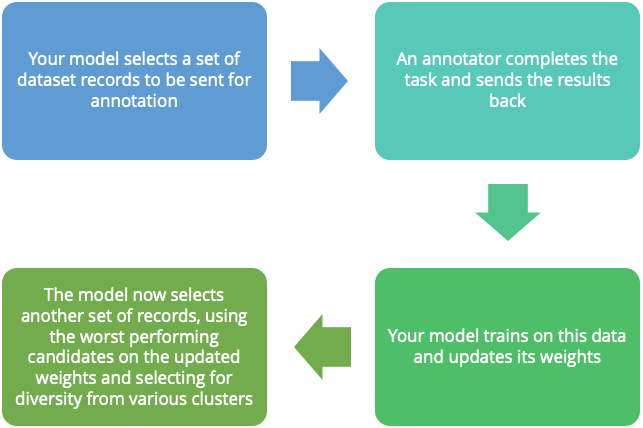
Here’s a standard storyline I’ve seen played out across organizations many times over: Lots of wasted resources. But critically, opportunities lost. Why does this happen, even
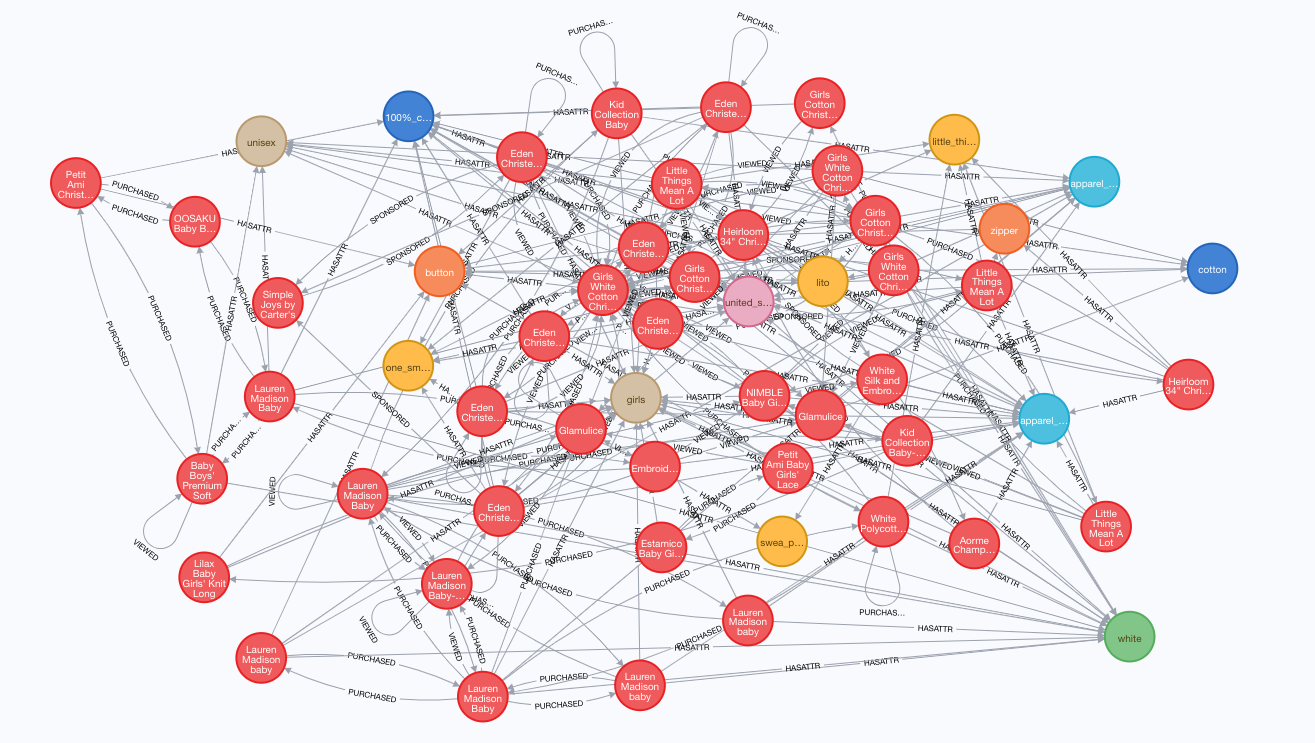
Over the past 7 years, we’ve built an extensive Universal Product Catalog, by curating and understanding public data from across the public e-commerce web. This
Imports, exports and tariffs are quite the theme in the news these days, be it in the context of Brexit, the US-China trade war or
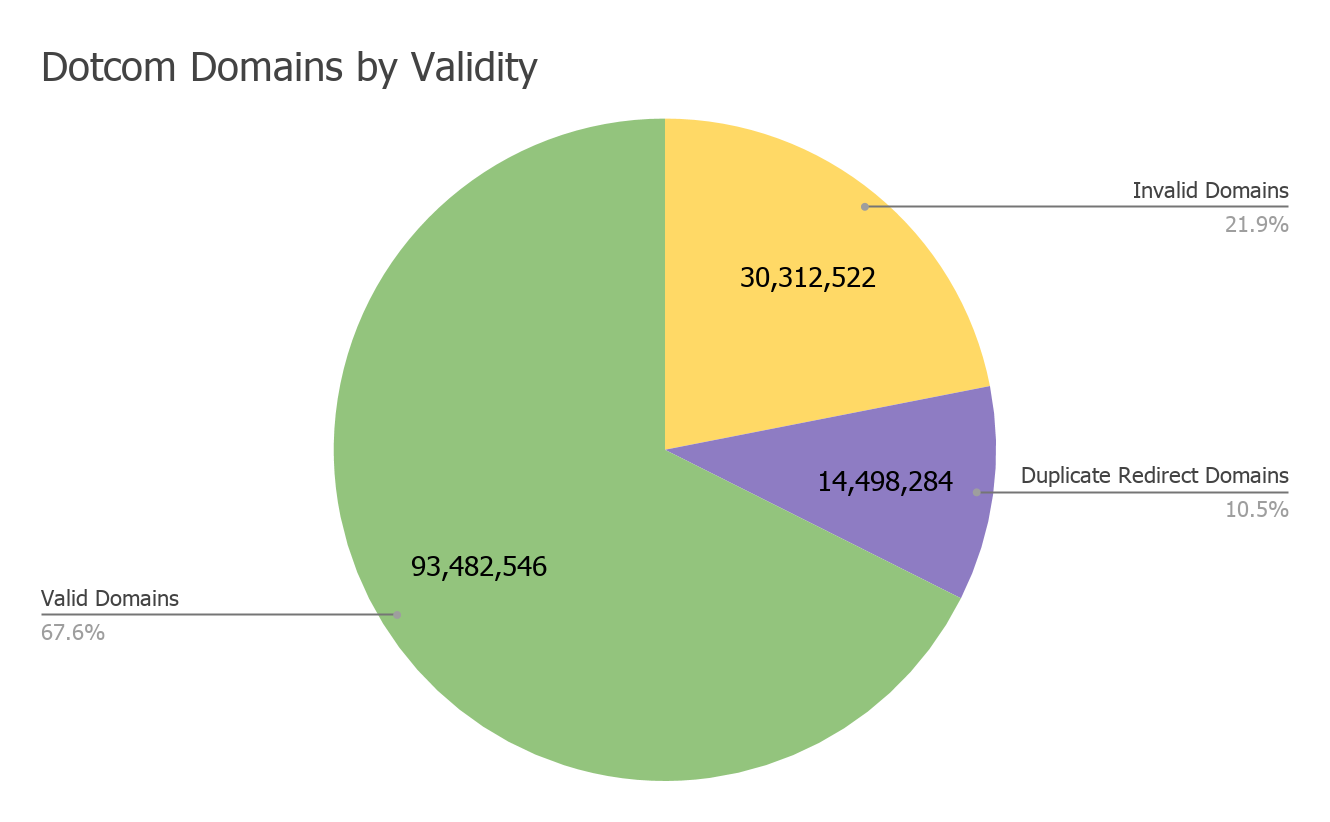
Over the course of two weeks in February 2019, two Semantics3 engineers crawled the entire universe of dotcom domains looking for ecommerce sites. We built

A couple of weeks ago, I posted a two part series detailing how we do data QA at Semantics3. In the days that followed, I’ve had people get
View More